 Your new post is loading...
Your new post is loading...

|
Scooped by
luiy
|
|
|
Rescooped by
luiy
from Papers
|
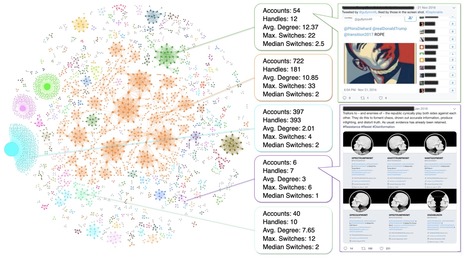
Coordinated campaigns are used to manipulate social media platforms and influence their users, a critical challenge to the free exchange of information. Our paper introduces a general, unsupervised, network-based methodology to uncover groups of accounts that are likely coordinated. The proposed method constructs coordination networks based on arbitrary behavioral traces shared among accounts. We present five case studies of influence campaigns, four of which in the diverse contexts of U.S. elections, Hong Kong protests, the Syrian civil war, and cryptocurrency manipulation. In each of these cases, we detect networks of coordinated Twitter accounts by examining their identities, images, hashtag sequences, retweets, or temporal patterns. The proposed approach proves to be broadly applicable to uncover different kinds of coordination across information warfare scenarios. By Diogo Pacheco, Pik-Mai Hui, Chris Torres, Bao Truong, Sandro Flammini & Fil Menczer Read the full open-access article from the Proceedings ICWSM2021
Via Complexity Digest
|
|
Scooped by
luiy
|
Social Network Analysis (SNA) is becoming an important tool for investigators, but all the necessary information is often available in a distributed environment. Currently there is n
|
|
Scooped by
luiy
|
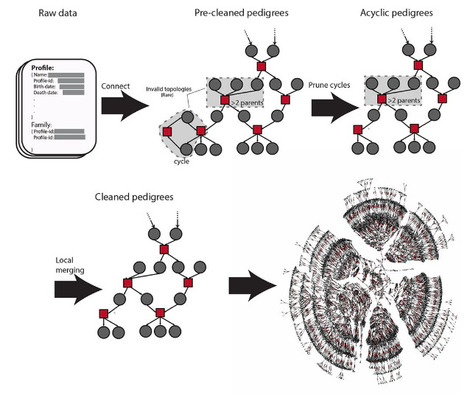
Family trees have vast applications in multiple fields from genetics to anthropology and economics. However, the collection of extended family trees is tedious and usually relies on resources with limited geographical scope and complex data usage restrictions. Here, we collected 86 million profiles from publicly-available online data shared by genealogy enthusiasts. After extensive cleaning and validation, we obtained population-scale family trees, including a single pedigree of 13 million individuals. We leveraged the data to partition the genetic architecture of longevity by inspecting millions of relative pairs and to provide insights into the geographical dispersion of families. We also report a simple digital procedure to overlay other datasets with our resource in order to empower studies with population-scale genealogical data.
|
|
Scooped by
luiy
|
From e-mails to social networks, the digital traces left by life in the modern world are transforming social science.
Infectious ideas In some instances, big data have showed that long-standing ideas are wrong. This year, Kleinberg and his colleagues used data from the roughly 900 million users of Facebook to study contagion in social networks — a process that describes the spread of ideas such as fads, political opinions, new technologies and financial decisions. Almost all theories had assumed that the process mirrors viral contagion: the chance of a person adopting a new idea increases with the number of believers to which he or she is exposed.
|
|
Scooped by
luiy
|
Building typologies allows to compare networks on multiple dimensions, and to approach a generalization grounded on empirical data. In this article, we present a typology of personal networks only based on indicators related to the structure of relations between alters. It is designed from very detailed data on young French people who were involved in a longitudinal study. Our typology mobilizes a small number of indicators to discriminate the types that compose it. In so doing, we intend to make it applicable to various surveys.
|
|
Scooped by
luiy
|
April 5, 2017—Yochai Benkler, professor at Harvard Law School and co-director of the Berkman Klein Center for Internet and Society at Harvard, discussed his recent study on conservative media and the 2016 election, which analyzed more than 1.25 millio
|
|
Scooped by
luiy
|
Shortly after the start of his campaign during the 2012 Mexican presidential election, then-candidate Enrique Peña Nieto (EPN) rose to Twitter dominance almost overnight. To some savvy Internet…
|
|
Scooped by
luiy
|
Why study fake news and digital misinformation
After the 2016 US elections, the topic of fake news and their spread on social media has become a hotly debated issue. As our group has been studying this phenomenon since 2010, our work has been covered and quoted in the media, analyzing the influence of social bots, the appearance of fake news in Facebook trends, vote suppression attempts, the magnitude of the problem, the potential of fake news in social media to sway elections, online advertising as incentives for fake news, the effectiveness of advertising bans, the steps taken by Facebook, the future of fake news, and the real consequences of conspiracy theories. Our editorial article in The Conversation has been republished widely, including by Time, Scientific American, and PBS. It is good that the problem of digital misinformation is getting the attention it deserves. Research investments are needed toward a deeper understanding of the phenomenon as well as toward socio-technical countermeasure to help mitigate the deceptive manipulation of opinions, without infringing on the free flow of information.
|
|
Scooped by
luiy
|
|
|
Scooped by
luiy
|
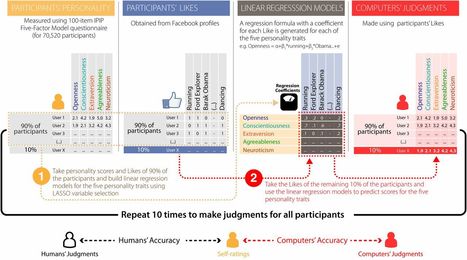
This study compares the accuracy of personality judgment a ubiquitous and important social-cognitive activity between computer models and humans. Using several criteria, we show that computers judgments of people's personalities based on their digital footprints are more accurate and valid than judgments made by their close others or acquaintances (friends, family, spouse, colleagues, etc.). Our findings highlight that people’s personalities can be predicted automatically andwithout involving human social-cognitive skills.
|
|
Rescooped by
luiy
from Papers
|
Online social media have greatly affected the way in which we communicate with each other. However, little is known about what are the fundamental mechanisms driving dynamical information flow in online social systems. Here, we introduce a generative model for online sharing behavior and analytically show, using techniques from mathematical population genetics, that competition between memes for the limited resource of user attention leads to a type of self-organized criticality, with heavy-tailed distributions of meme popularity: a few memes "go viral" but the majority become only moderately popular. The time-dependent solutions of the model are shown to fit empirical micro-blogging data on hashtag usage, and to predict novel scaling features of the data. The presented framework, in contrast to purely empirical studies or simulation-based models, clearly distinguishes the roles of two distinct factors affecting meme popularity: the memory time of users and the connectivity structure of the social network. Determinants of Meme Popularity
James P. Gleeson, Kevin P. O'Sullivan, Raquel A. Baños, Yamir Moreno http://arxiv.org/abs/1501.05956
Via Complexity Digest
|
|
Scooped by
luiy
|
|
|
|
Rescooped by
luiy
from Amazing Science
|
B-SOiD is an open source, unsupervised algorithm that can discover and identify behaviors without user input. To Eric Yttri, assistant professor of biological sciences and Neuroscience Institute faculty at Carnegie Mellon University, the best way to understand the brain is to watch how organisms interact with the world. "Behavior drives everything we do," Yttri said. As a behavioral neuroscientist, Yttri studies what happens in the brain when animals walk, eat, sniff or do any action. This kind of research could help answer questions about neurological diseases or disorders like Parkinson's disease or stroke. But identifying and predicting animal behavior is extremely difficult. Now, a new unsupervised machine learning algorithm developed by Yttri and Alex Hsu, a biological sciences Ph.D. candidate in his lab, makes studying behavior much easier and more accurate. The researchers published a paper on the new tool, B-SOiD (Behavioral segmentation of open field in DeepLabCut), in Nature Communications. Previously, the standard method to capture animal behavior was to track very simple actions, like whether a trained mouse pressed a lever or whether an animal was eating food or not. Alternatively, the experimenter could spend hours and hours manually identifying behavior, usually frame by frame on a video, a process prone to human error and bias. Hsu realized he could let an unsupervised learning algorithm do the time-consuming work. B-SOiD discovers behaviors by identifying patterns in the position of an animal's body. The algorithm works with computer vision software and can tell researchers what behavior is happening at every frame in a video. "It uses an equation to consistently determine when a behavior starts," Hsu explained. "Once you reach that threshold, the behavior is identified, every time. A human experimenter might toggle between two frames or several categories, try to decide where behavior begins and become fatigued over time." Yttri said B-SOiD provides a huge improvement and opens up several avenues for new research. "It removes user bias and, more importantly, removes the time cost and arduous work," he said. "We can accurately process hours of data in a matter of minutes." Additionally, B-SOiD is very user friendly and openly available to any researcher. Yttri's lab and their collaborators have used the new algorithm in research on many important areas, including research to better understand chronic pain, obsessive compulsive disorder and more. Collaborators have even begun to use B-SOiD to study human movement in Parkinson's disease. "We are beginning to see if this can be used as part of an objective test by a doctor to show how far a patient's disease has progressed. The hope is that a patient anywhere in the world would be diagnosed with one standardized metric," Yttri said. This is a breakthrough in how scientists can study natural behavior and how it changes rather than the overly simplistic or subjective measures that predominate neuroscience and ethology.
Via Dr. Stefan Gruenwald
|
|
Rescooped by
luiy
from Papers
|
Ranking online social users by their Influence
Anastasios Giovanidis, Bruno Baynat, Clémence Magnien & Antoine Vendeville
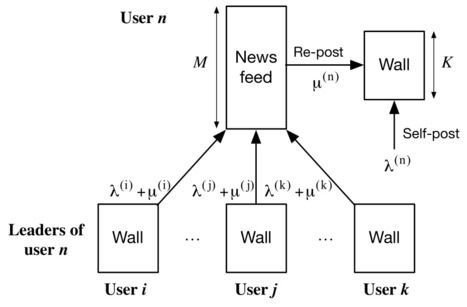
IEEE/ACM Transactions on Networking ( Early Access ) (2021) DOI: 10.1109/TNET.2021.3085201 Date of Publication: 08 June 2021 This work introduces an original mathematical model to analyze the diffusion of posts within a generic online social platform. The main novelty is that each user is not simply considered as a node on the social graph, but is further equipped with his/her own Wall and Newsfeed, and has his/her own individual self-posting and re-posting activity. As a main result using the developed model, the probabilities that posts originating from a given user are found on the Wall and Newsfeed of any other can be derived in closed form. These are the solution of a linear system of equations, which can be resolved iteratively. In fact, the new model is very flexible with respect to the modeling assumptions. Using the probabilities derived from the solution, a new measure of per-user influence over the entire network is defined, named the Ψ-score, which combines the user position on the graph with user (re-)posting activity. In the homogeneous case where all users have the same activity rates, it is shown that a variant of the Ψ-score is equal to PageRank. Furthermore, the new model and its Ψ-score are compared against the empirical influence measured from very large data traces (Twitter, Weibo). The results illustrate that these new tools can accurately rank influencers with asymmetric (re-)posting activity for such real world applications. Read the full article at: ieeexplore.ieee.org
Via Complexity Digest
|
|
Scooped by
luiy
|
Cover stories offer a look at the process behind the art on the cover: who made it, how it got made, and why.
This cover (Fig. 1) depicts the breadth and depth of the spread of two different news stories through Twitter (see the Report by Vosoughi et al.). The larger orange object (or cascade) represents a false news story, whereas the teal one represents a true news story. I aimed to illustrate the stark differences in how broadly and deeply false news spreads compared with true news, which are reflected in the relative size and complexity of the cascades.
|
|
Scooped by
luiy
|
Dow Jones Digital Reprints & Licensing
|
|
Scooped by
luiy
|
|
|
Scooped by
luiy
|
Graphcore Poplar software framework images of machine learning executed as a graph on the IPU Intelligent Processing Unit. Graph computing explained visually.
A graph is simply the best way to describe the models you create in a machine learning system. These computational graphs are made up of vertices (think neurons) for the compute elements, connected by edges (think synapses), which describe the communication paths between vertices.
|
|
Scooped by
luiy
|
In our collaborative op-ed for Sam Woolley’s provocateur-in-residence workshop at Data & Society, How to Think About Bots, we briefly surveyed the role bots can play in journalism. As we said in our…
|
|
Scooped by
luiy
|
Is social media a valid indicator of political behavior? There is considerable debate about the validity of data extracted from social media for studying offline behavior. To address this issue, we show that there is a statistically significant association between tweets that mention a candidate for the U.S. House of Representatives and his or her subsequent electoral performance. We demonstrate this result with an analysis of 542,969 tweets mentioning candidates selected from a random sample of 3,570,054,618, as well as Federal Election Commission data from 795 competitive races in the 2010 and 2012 U.S. congressional elections. This finding persists even when controlling for incumbency, district partisanship, media coverage of the race, time, and demographic variables such as the district's racial and gender composition. Our findings show that reliable data about political behavior can be extracted from social media.
|
|
Scooped by
luiy
|
The identification of nodes occupying important positions in a network structure is crucial for the understanding of the associated real-world system. Usually, betweenness centrality is used to evaluate a node capacity to connect different graph regions. However, we argue here that this measure is not adapted for that task, as it gives equal weight to "local" centers (i.e. nodes of high degree central to a single region) and to "global" bridges, which connect different communities. This distinction is important as the roles of such nodes are different in terms of the local and global organisation of the network structure. In this paper we propose a decomposition of betweenness centrality into two terms, one highlighting the local contributions and the other the global ones. We call the latter bridgeness centrality and show that it is capable to specifically spot out global bridges. In addition, we introduce an effective algorithmic implementation of this measure and demonstrate its capability to identify global bridges in air transportation and scientific collaboration networks.
|
|
Scooped by
luiy
|
|
|
Rescooped by
luiy
from Papers
|
In this work we study a peculiar example of social organization on Facebook: the Occupy Movement -- i.e., an international protest movement against social and economic inequality organized online at a city level. We consider 179 US Facebook public pages during the time period between September 2011 and February 2013. The dataset includes 618K active users and 753K posts that received about 5.2M likes and 1.1M comments. By labeling user according to their interaction patterns on pages -- e.g., a user is considered to be polarized if she has at least the 95% of her likes on a specific page -- we find that activities are not locally coordinated by geographically close pages, but are driven by pages linked to major US cities that act as hubs within the various groups. Such a pattern is verified even by extracting the backbone structure -- i.e., filtering statistically relevant weight heterogeneities -- for both the pages-reshares and the pages-common users networks. Structural Patterns of the Occupy Movement on Facebook
Michela Del Vicario, Qian Zhang, Alessandro Bessi, Fabiana Zollo, Antonio Scala, Guido Caldarelli, Walter Quattrociocchi http://arxiv.org/abs/1501.07203
Via Complexity Digest
|
|
Rescooped by
luiy
from Papers
|
The first network analysis of the entire body of European Community legislation reveals the pattern of links between laws and their resilience to change.
Via Complexity Digest
|





















![[1509.08295] Detecting global bridges in networks | Influence et contagion | Scoop.it](https://img.scoop.it/-h6islTtTAqZQIJdsey-uDl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)







The phenomenon of social contagion—that information, ideas, and even behaviors can spread through networks of people the way that infectious diseases do—is both intuitively appealing and potentially powerful.
It appeals to our intuition for two reasons. First, it is obviously true that people are influenced by one another. Reflecting on our individual experience of life, it is easy to recall any number of instances in which we have been influenced, whether by our parents, our teachers, our coworkers, or our friends, and corresponding instances when we have influenced them. And second, once you accept that one person can influence another, it follows logically that that person can influence yet another person, who can in turn influence another person, and so on. Influence, that is, can spread.