 Your new post is loading...
Your new post is loading...



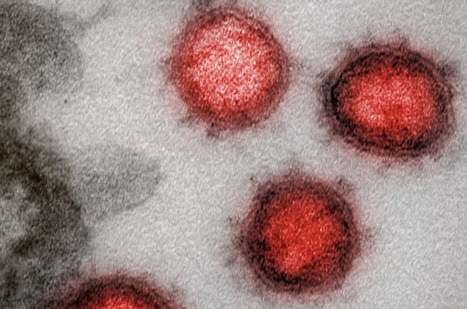
The coronavirus is an oily membrane packed with genetic instructions to make millions of copies of itself. The instructions are encoded in 30,000 “letters” of RNA — a, c, g and u — which the infected cell reads and translates into many kinds of virus proteins. In December, a cluster of mysterious pneumonia cases appeared around a seafood market in Wuhan, China. In early January, researchers sequenced the first genome of a new coronavirus, which they isolated from a man who worked at the market. That first genome became the baseline for scientists to track the SARS-CoV-2 virus as it spreads around the world.
A cell infected by a coronavirus releases millions of new viruses, all carrying copies of the original genome. As the cell copies that genome, it sometimes makes mistakes, usually just a single wrong letter. These typos are called mutations. As coronaviruses spread from person to person, they randomly accumulate more mutations. The genome below came from another early patient in Wuhan and was identical to the first case, except for one mutation. The 186th letter of RNA was u instead of c. When researchers compared several genomes from the Wuhan cluster of cases they found only a few new mutations, suggesting that the different genomes descended from a recent common ancestor. Viruses accumulate new mutations at a roughly regular rate, so the scientists were able to estimate that the origin of the outbreak was in China sometime around November 2019.
Outside of Wuhan, that same mutation in the 186th letter of RNA has been found in only one other sample, which was collected seven weeks later and 600 miles south in Guangzhou, China. The Guangzhou sample might be a direct descendent of the first Wuhan sample. Or they might be viral cousins, sharing a common ancestor. During those seven weeks, the Guangzhou lineage jumped from person to person and went through several generations of new viruses. And along the way, it developed two new mutations: Two more letters of RNA changed to u....